Organize your Incident Response Program - pt 1


A well-organized cyber security incident response (IR) program can certainly make the difference between a bad day and a bad week in the face of a serious incident, but with some extra work up front you can set yourself up for great metrics and reporting programs, organized alert tuning, and smooth on-boarding of new analysts to your security operations center (SOC).
I'm going to go over some practical tips and documents that I've found to increase the efficacy and efficiency of my IR programs.
Priority/Severity Ranking
You should have a system in place for marking how serious an event/incident was. Even a simple 1-5 based on gut feelings is better than nothing. A more "mature" option would be to have a set of severity & scope criteria assigned in your playbooks. This should be calculated when triaging the alert, but might change as more information is discovered.

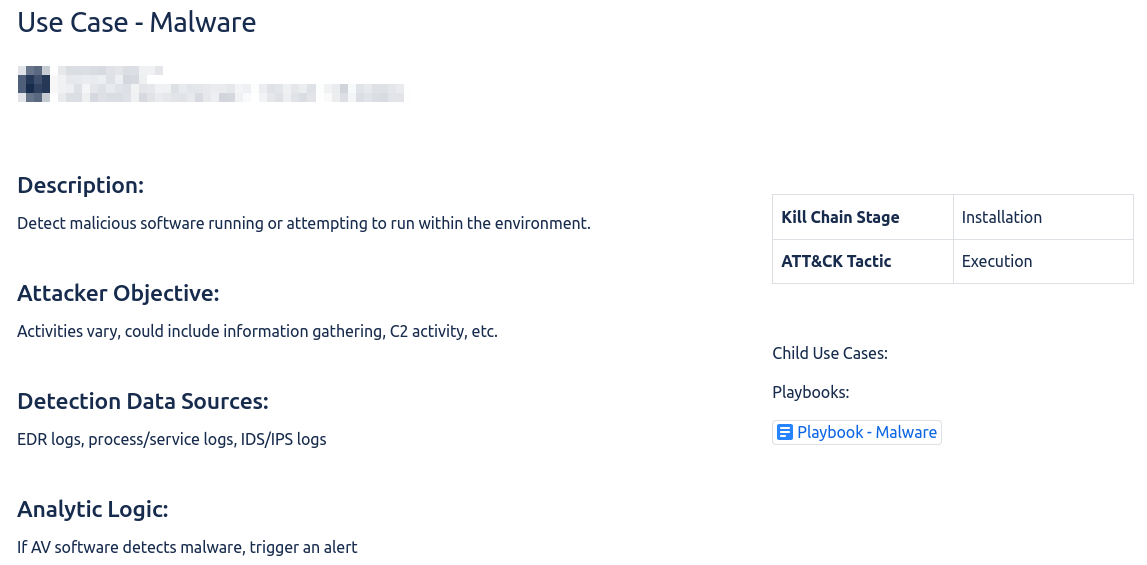
Use Cases
A use case is a document that explains why the IR team is concerned with a certain type of behavior. These are great for organizing your thoughts and help analysts see the bigger picture. A description, attacker objective, data sources for detection, and detection logic can all be helpful here. These can be more or less specific depending on your teams needs, but generally these cover large categories of potential incidents:
Playbooks
What to do when you get that alert. This has been well covered by others and you can find lots of good examples on the web. I'll have some links at the bottom of the article.
Organize your alerts
Whatever system you have for finding the bad should be well documented. A simple table with some key points will do you wonders.

Here is a breakdown of the table elements:
- ID - Unique ID for this alert
- Description - what this alert looks for, in simple language
- Platform - where this alert comes from (SIEM, IDS, EDR, etc.)
- Query - specific to SIEM alerts, but what exactly you are looking for
- Type & Status - Will cover these more below
- Schedule - how often this alert runs if on a specific schedule
- Use Case - Why you are looking for this type of activity
- Playbook - What to do when you see this alert
Type
Type is an indicator of an alert's specificity and categorizes alerts by how likely they are to detect actual malicious behavior. I've boiled this down to a few levels:
- Anomaly - a weird thing happened, it's probably not bad
- Investigate - probably bad, but additional information is needed to determine
- High-fidelity - Almost certainly bad
Status
Status is the status of the alert logic itself.
- Experimental - Testing feasibility, in development
- Functional - Still tuning, investigate with some care
- Stable - Thoroughly vetted and stable, should not change unless something else changes
Make a ticket
Tickets are love. Tickets are life. This is the only thing I consider non-negotiable. When I say "a ticket" I mean some sort of quasi-permanent record containing information about the event/incident. Any time your team is investigating or responding to something there should be a unique record of that event that says what happened and what you did about it. You will need to find these in the future for analysis. You probably already have this. If you are running your IR program out of a Slack channel... gross.
Tickety Goodness
So, what goes in the ticket? What the incident/event was & what you did about it are key, but these tickets are going to drive your metrics & measures program and your alert tuning.
Use Cases that should go in there. So should the playbook. Now you are tracking what kind of events you are seeing. If you are creating tickets automatically based on alerts you can probably put these in from the start. Now you have a quick reference for what an event means and how to respond to it.
Scope, severity, and priority will be established by the SOC team during the triage process and possibly updated during investigation.
Alert ID should be tied to every ticket. What alert was this made for? I suggest having documented alert types for things like "support saw a weird thing" & "user reported event."
Every ticket should be marked as a true or false positive. You can have subcategories of these if you want, but a binary decision is probably best to start with.
Timestamps of when a ticket was open and when it went through various steps of the playbook can be helpful for measuring parts of SOC performance such as time-to-triage and time-to-resolve.
Putting it Together
What you have now is a single artifact that contains not only everything you need to work on the incident now, but quite a few useful things for the future:
- What happened
- How bad was it
- What that means and why it's bad
- How it should be handled & actual remediation steps.
- Where the alert came from and how it works
- If the alert is working properly and identifying the targeted behavior

Thank You
In a future article I will go over additional advice on creating a metrics & measures program for your SOC using this data.
If you have any questions please reach out into the psychic maelstrom and astral project them to me.
Links & References




