Organize your Incident Response Program - pt 2 - Measurements & Metrics


Welcome back to another thrilling day of infosec management. Today we are going to take everything we learned in part 1 and turn it into a fearsome tool you can use to impress your friends, motivate your team, and banish your auditors back to their dark domain. I'm speaking of the much maligned metrics & measures program.
I'll be the first to say that I don't think this approach is perfect, but it's a relatively simple way to get started measuring an IR program that I've found to provide good value. I suggest establishing a regular cadence (monthly is probably a good starting point) for gathering these and keeping the results in a centralized place.
Measures & Metrics
First, let's get some terminology out of the way.
A measure is a concrete, objective attribute. Measures have units and a numerical value. How many high severity issues did we have last week? How many alerts did we get for alert rule X? How many false positives did we have?
A metric is a measure or set of measures compared to some kind of objective in order to assess performance. Metrics can be largely subjective, but should still be based on things you can measure.
Basic Measures
Everything we covered in part 1 can be measured. That's the beauty of having a single record per incident with all of the required information.
- Basics
- Incident count
- Number of true/false positives
- Median/average time to triage/close/whatever makes sense for your process.
- Split it up
- Incident count by severity, alert, and use case.
- True/false positives by alert
- Time to close/triage/contain by alert or use case
Designing Metrics
So now you have a bunch of numbers. Good for you. Now we must attempt to extract something meaningful from them. Metrics should be designed with the goal of monitoring and improving the health of your program. The tricky part is that metrics are inherently subjective and as such only as meaningful as you want them to be. A key thing to remember is that if you aren't meeting a metric it could be indicative of a problem or it could mean that your goal is just wrong. I suggest gathering at least a few weeks or months worth of data before designing any metrics.
Your metrics should be beneficial to you and the rest of the IR team. They should highlight successes and areas for improvement. What is working well and where do we need to focus our improvements.
Here are a couple of examples that I have found to be quite valuable:
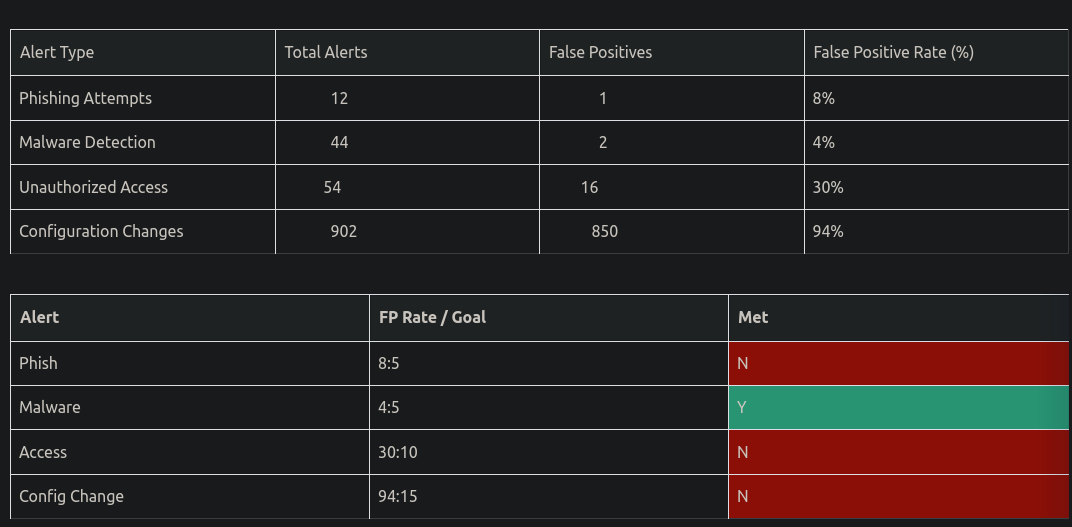
Alert X should have a true positive to false positive ratio of Y:1
How accurate are your alerts? Which need tuning, enriching, or even retirement? False positives aren't world ending (as many vendors would have you believe), but they should be monitored. What the appropriate level is depends on the type and status of the alert.
Below we have two tables, the top one calculating the rate of false positives for a given period (measures) and the bottom showing those rates as compared to goal rates (metric). For phishing incidents we have 1 false positive out of 12 total alerts for an 8% false positive rate. Our goal is 5%. Since we had a false positive rate over our goal, we didn't meet our metric. Now what do we do about it?
Time to initial alert triage should be less than X minutes.
If you are going to capture one time-based metric I think this is the one. How long does it take for a responder to look at an incident and assign it a priority. Everything that happens after this has a lot of variables and as such can be much harder to get value from. Time-to-triage has been valuable for me in tuning alert levels, staffing, and where to focus automation efforts.
If your ticketing system timestamps when an issue goes through a particular workflow step, you should be able to take the timestamp of when it was triaged minus the timestamp of when it was opened to get how long it took to triage that issue. I like to do this in Python with datetime and statistics, but you could probably do it in Excel if you hate yourself.
I suggest calculating both the mean and median for any "average" measures, but build your metrics off one or the other.
for issue in statuslog:
for status_change in issue:
from_status = status_change[0]
to_status = status_change[1]
if to_status == "Open":
open_time = status_change[2]
if to_status == "Ready":
triage_complete_time = status_change[2]
time_to_triage = triage_complete_time - open_time
all_triage_deltas.append(time_to_triage)
if to_status == "Closed":
close_time = status_change[2]
time_to_close = close_time - open_time
all_close_deltas.append(time_to_close)
```Leveraging Metrics
So, you didn't meet your goal. Why? Well, that's going to be on you, but hopefully you have discovered a problem with a process. If you have appropriate data leading up to this point you should have everything you need to figure out what that problem is and how you can solve it. For example, if your false positive rate is slightly high, maybe your alert could use some tuning or additional enrichment. If your false positive rate is extremely high and is always extremely high then maybe your alert is bad and you should put it out of it's misery. If your time to triage is too high maybe you are generating more alerts than your team can reasonably work or maybe you are not appropriately prioritizing triage over other types of work.
Compliance Goals
Something as simple as a few measures and handful of decent metrics should cover any compliance requirements around monitoring and continuous improvement of your IR program for ISO 27001/27002, SOX, whatever. I'm not your auditor, but it's worked for me.
In Closing
Hopefully this has been at least somewhat helpful. If you have questions, comments, or concerns you can join us on the CrankySec Discord




